

统计学院本学期数据科学学术研讨班收官
2022年,统计学院突出学科建设在学院发展中的关键作用,着力支持四支学术团队(方向)开展协同合作。疫情期间,数据科学团队不断加强团队建设,在家教研办公不放松,高质量开展定期学术研讨。
本学期,学院数据科学团队每两周定期开展学术研讨,吸纳团队教师、在读研究生和部分本科生参与,共开展6次、每期讨论时长超过三小时,从12个主题中协同讨论,分享工作进展。
概率图模型与近似推断。概率图模型是人工智能领域中使用的重要统计方法,林鹏做了其近期科研工作的报告,就大规模模型近似推断问题进行了研讨。

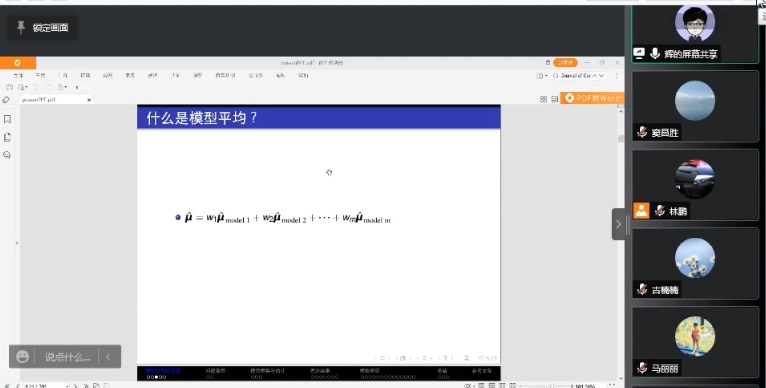
模型平均。模型平均方法是统计学和计量经济学中活跃的方法,邹家辉对领域的脉络进行了详尽地介绍,并就发散维度的Poisson回归模型给出了具体的模型平均估计改造方法。
社交网络。在社交网络中,恶意用户的存在会造成很多不利影响后果,为了减少它们的负面影响,理性的用户有必要仔细识别并与每个邻居交互,以保护自己免受恶意攻击。李琳就社交网络中引入声誉机制的进化博弈论进行了汇报。

图像检索。近年来,细粒度图像检索(FGIR)已成为计算机视觉领域的一个研究热点,该领域的大多数高级检索算法主要集中在损失函数和硬样本挖掘策略的设计。李晓晴从另一个角度分析FGIR算法的性能并提出注意事项,介绍了基于机制和上下文信息约束的图像检索(AMCICIR)。

手势识别。对具有复杂内在特征的多维数据进行分类是一个具有挑战性的问题,如基于视频的人体手势识别。特别地,流形结构是表征多维系统内在几何结构的一种好方法。王玉萍针对该方法介绍了表示人类手势视频流形(PGM)的高阶奇异值分解(HOSVD)的数据张量,以及一种加权稀疏编码模型PGM。
文本分类。利用计算机理解政治观点形成事件,在新闻传播的巨大变化的背景下,变得越来越重要。周振坤介绍了一个新的框架,使用来自丰富的社会和语言背景的信号预先训练文本模型从而实现观点的提取。

网络数据蠕虫检测。近年来,移动互联网极大地促进了人们的日常生活。然而,它已经成为许多新蠕虫的滋生地,包括基于蓝牙的蠕虫,基于短信/彩信的蠕虫和基于Wi-Fi的蠕虫。窦昌胜利用网络结构特征分析了计算机蠕虫的传播规律。
半监督自步学习。半监督分类是模式识别和机器学习领域的一个研究热点,然而,在存在强噪声和异常值的情况下,未标记的训练数据对于半监督分类器来说是一个非常具有挑战性甚至误导性的问题。古楠楠介绍了一种新的结构正则化半监督自学习方法来处理分类问题,可以有效地学习部分标记的训练数据。

复杂网络。科学家已经证明,许多复杂网络的特殊结构特征支持无需全球知识的高效沟通。马丽丽介绍了一种基于节点相似性的机制,通过应用该概念来探索模块化网络的形成复杂网络的隐藏度量空间。
不平衡数据分类。在大数据时代背景下,分类决策问题变得越来越重要,而在实际应用中,不平衡分类问题广泛存在着,如金融信用评估、诈骗号码识别、疾病诊断、网络安全检测等领域,数据的不平衡性使得传统的分类算法对少数类样本产生较差的分类效果。宋捷将数据层面的最优比例重抽样技术(OP)与算法层面的投影寻踪分类树算法(PPT)相结合(OPPPT)。
高维数据分析是近些年数据科学发展中的热点问题。安百国梳理了高维数据的统计分析研究的进展和成果,从不同角度概括高维统计研究的切入点,重点针对高维数据的结构研究进行综述。
呼叫数据模型。电话调查是一项常见的社会互动,如何才能提高电话调查的效率是一个值得深入探究的问题。李秋雅通过详尽的数据分析方法探究了一些影响因素,并给出了建议。
团队教师在活动开展期间对所选主题开展研讨互动,增进了交流合作,取得良好效果,有力提升了团队研究可持续性和协同性。
首经贸新闻网版权与免责声明: ①凡本网未注明其他出处的作品,版权均属于首经贸新闻中心,未经本网授权不得转载、摘编或利用其它方式使用上述作品。已经本网授权使用作品的,应在授权范围内使用,并注明“来源:首经贸新闻网”。违反上述声明者,本网将追究其相关责任。 ② 凡本网注明其他来源的作品,均转载自其它媒体,转载目的在于传递更多信息,并不代表本网对其负责。 ③ 有关作品内容、版权和其它问题请与本网联系。 ※ 联系方式:首经贸新闻中心 Email:xcb@cueb.edu.cn